
決まったポーズや構図の画像をプロンプトで作るのは非常に難しいです。
何度もプロンプトを修正して作りこんだプロンプトでも思い通りにいかなかったりしますよね。
ポーズや構図を指定して画像を生成するには
Img2ImgのControlNetをつかうと便利です。
ControlNetとは元となる画像のポーズや構図をベースに画像を再生成する機能です。
Leonardo.Ai は面倒なセットアップなしで、ControlNetを使うことが出来ます。
ControlNetを使うと好きなポーズ、思い通りの構図で画像を生成できるようになります。
ControlNetとは
Image2Imageが元画像から選択したモデルと画風で画像を生成するのに対して、ControlNet はポーズ、輪郭、深度情報、などの要素を抽出して、画像に反映させます。
ControlNetを使うことで元の構図を生かして画像を再生成することが可能になります。
サイドバーにある ControlNet ボタンは通常グレーアウトしています。
サイドバー下部にあるimg2img用のドロップエリア(↑の表示されているエリアです)に写真素材等を登録することで選択可能になります。
Prompt Magicのタブが有効になっていると切替が出来ないのでImage to Imageを使う場合はPrompt Magicをオフにします。
Image2image
ControlNetを使う前に、違いが判るようにまずはimg2imgで出力される画像を見ておきます。
元となる写真は、Leonardo.Aiで生成したものや、Community feed内の画像も指定できます。
今回は写真ACというサイトからダウンロードした写真をAi Canvasで加工したものを使います。
上半身だけの素材から不足している下半身をAi Canvasで追加しました、下半身が違和感がある状態ですがこちらを使用してきます。

元画像は使用する生成モデルに合わせてあらかじめサイズ変更しておきます。
今回は3D Animation Styleというモデルを使用するので、あらかじめ640×832のサイズに合わせた写真を用意しました。
画面左下のドロップエリアに元となる画像を登録します。
画像が登録できない場合
Prompt Magicをオフにすると画像がアップロードできるようになります。
画像がはじかれる場合はPrompt Magicのタブを確認してください。
生成済みの画像からImage2Imageを選択します。
今回はポーズを固定しながら別のキャラクターや衣装、画風を変えていきます。
プロンプトを入力します。
写真下部に表示される Init Strength は、元画像をどれだけ結果に反映させるかの初期強度をあらわしています。
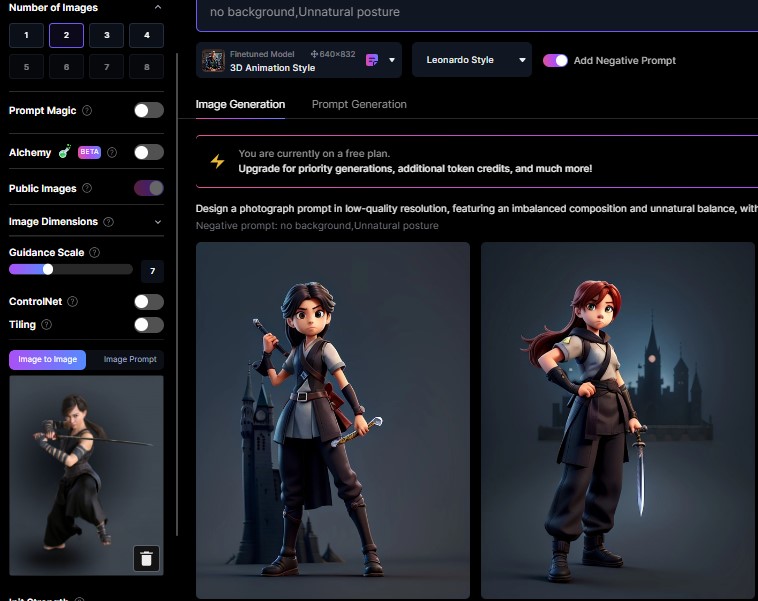
元の画像から反映されているのは全体の中での立ち位置でしょうか。
背景が追加されています。
元の画像の反映が弱かったのでポーズが反映されていないようです。
反映する強度を強くしていきます。
Init Strengthを0.5まで引き上げて再度Generateします。

似たようなポーズで生成されましたが、若干構図が変わっています。
生成された画像を元にimage2imageで繰り返し行っていくことも出来ますが何度か繰り返す必要があります。
ControlNet
次に ControlNet 機能を使っていきます。
Pose to Image/Edge to Image/Depth to Image の3つのモードを選択することができます。
また、各モードの違いが分かりやすいように影響の強さを表す ControlNet Weight は最大値の1のまま変更せずに進めます。
Pose to Image
まずは Pose to Image を選択した状態で画像生成していきます。
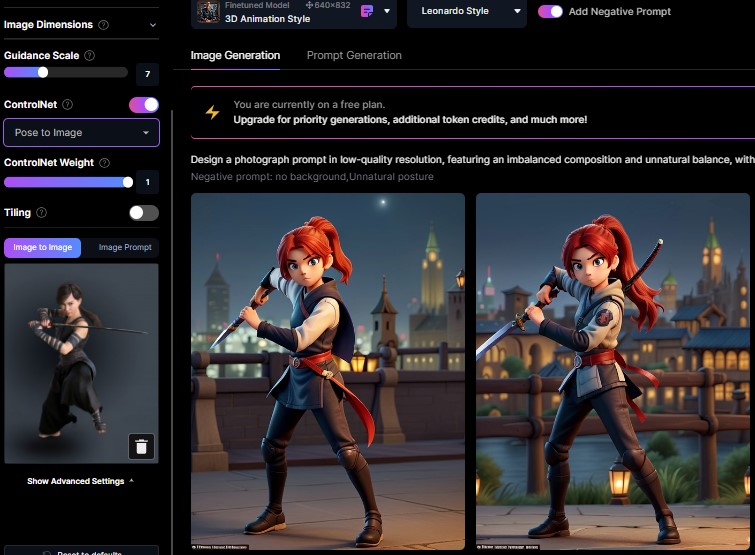
刀の向きや構図は多少異なるものの、元画像の「ポーズ」は結果に反映されているように見えます。
Image2imageでは反映されていなかった背景がプロンプトによって生成されています。
Pose to Image を使うことで、人物のポーズ以外はプロンプトによって自由に生成することが可能です。
- ポーズが若干変わる
Edge to Image
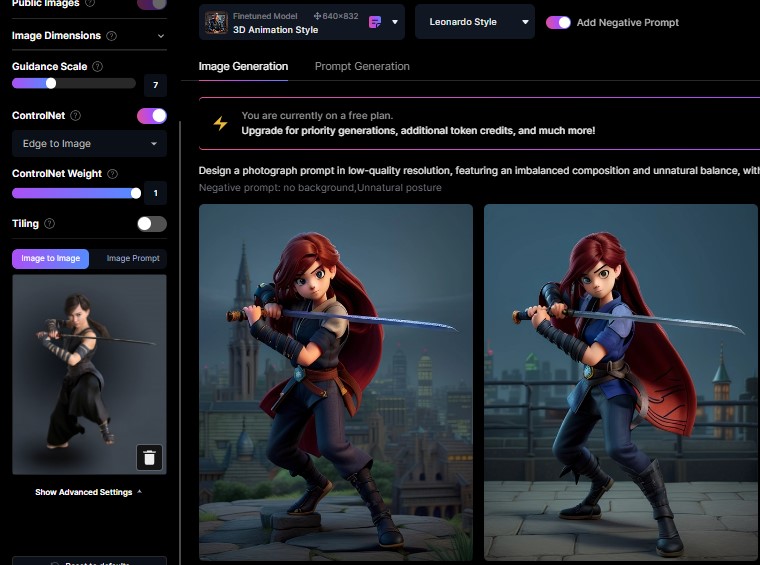
今度は写真の輪郭のみを反映した場合です。
服装や肌の境界線や、手の位置は先程よりも再現度が高く刀の向きがしっかりと反映されています。
Edge to Image は輪郭を抽出してくれるので、手書きのラフスケッチをAIに仕上げてもらうという使い方に向いています。
- 輪郭を抽出して反映する
Depth to Image
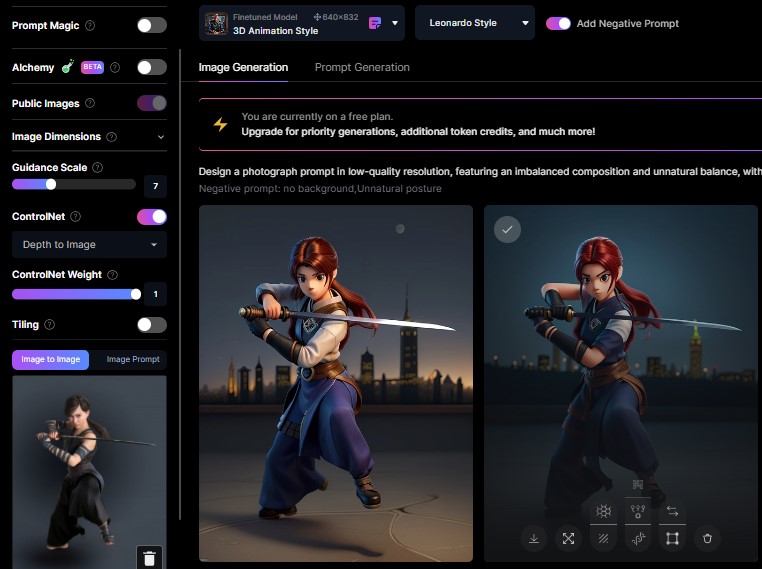
こちらは元画像から生成した「深度マップ」を使って生成されたイメージです。
画像内の各ピクセルに対して数値を割り当てることで元の画像の再現率を高めます。
3つのモードのうち、元写真の位置関係を最も忠実に再現しているのがこれかなと思います。
左足があがっている様子や髪型が3つのモードの中で一番忠実に再現されています。
今回試した中では Depth to Image が最も好印象な結果となりました。
Depth to Image は「全体の構図を忠実に再現する」という視点で見ればよい結果を出してくれます。
- 元の画像を忠実に再現する
まとめ
今回はポーズを指定するControlNetと各モードの違いについて説明をしました。
ControlNetを使えばイメージ通りの画像が生成しやすくなります。
元となるポーズや構図は複数素材を組み合わせて合成したものから仕上げをControlNetで行うという使い方も出来ます。
同じ素材から画風を変えることも出来るので作れる画像の幅が広がりますよね。
またControlNetと合わせて使いたい機能に画像を編集できるAi Canvasがあります。
色を変えたり、一部を変えたりすることが出来る機能です。
詳細はこちらの記事にありますので、ぜひご覧ください。














コメント